안녕하세요 오늘은 네이버 길찾기사이트로 들어가 자동으로 입력하고 자동으로 길찾기 버튼을 눌르면서 몇시간 걸리는 지에 대해 알아보겠습니다.
1. webdrive와 selenium을 설치하셔야 됩니다.
네이버 길찾기 페이지를 들어갑니다.
https://map.naver.com/v5/directions/-/-/-/?c=14139078.9231079,4509745.6215210,15,0,0,0,dh
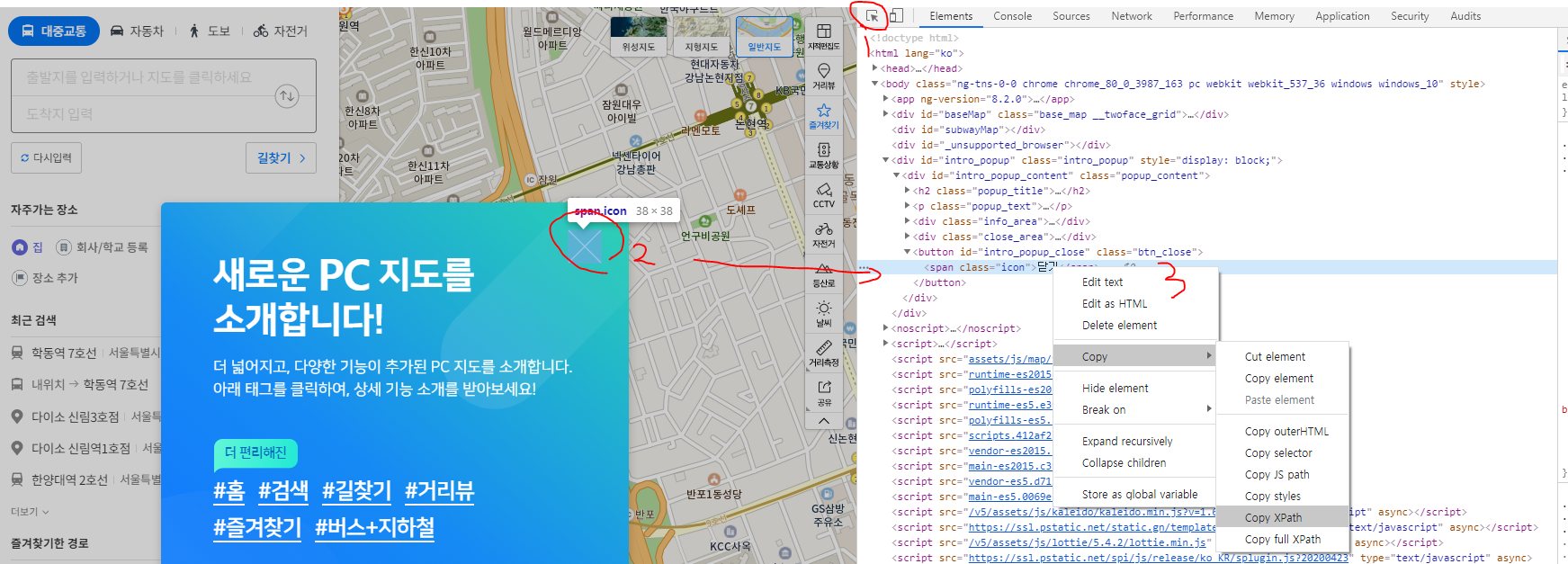
CTRL + ALT + I 을 눌러 페이지의 소스를 봐야됩니다.
그런다음 차례대로 1번을 실행합니다. 3번째의 XPATH를 복사해서 메모장 OR 파이썬에 저장합니다. XPATH는 다음과 같습니다.
//*[@id="intro_popup_close"]/span
그리고 이제 출발지 안에 값을 입력해야 됩니다.
출발지 값은 다음과 같습니다.
id값 : directionStart
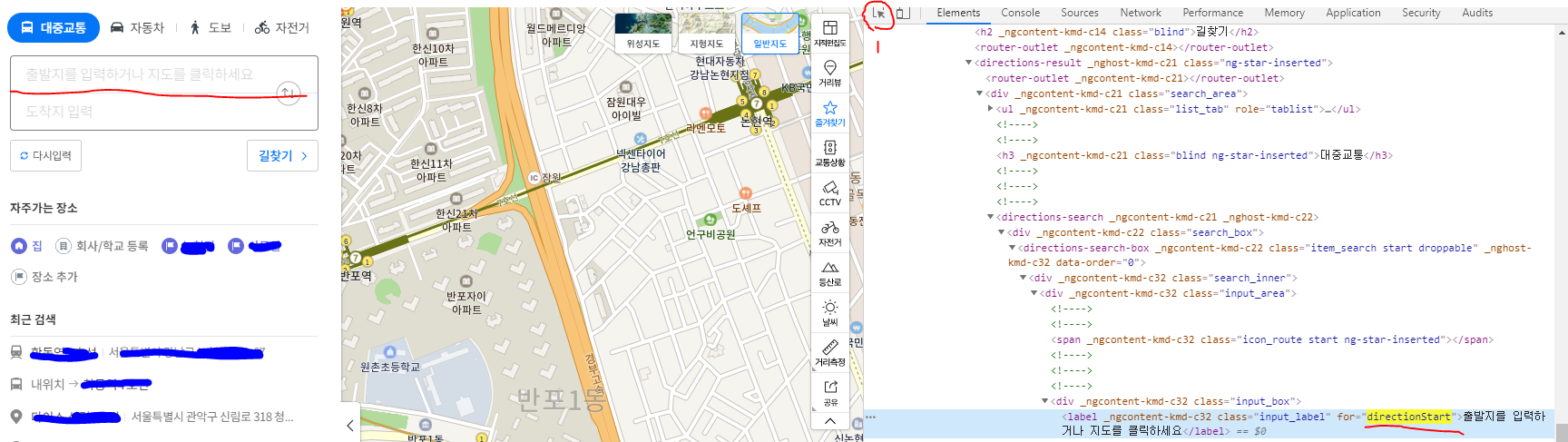
이제 잠실역이라는 값을 받았으면
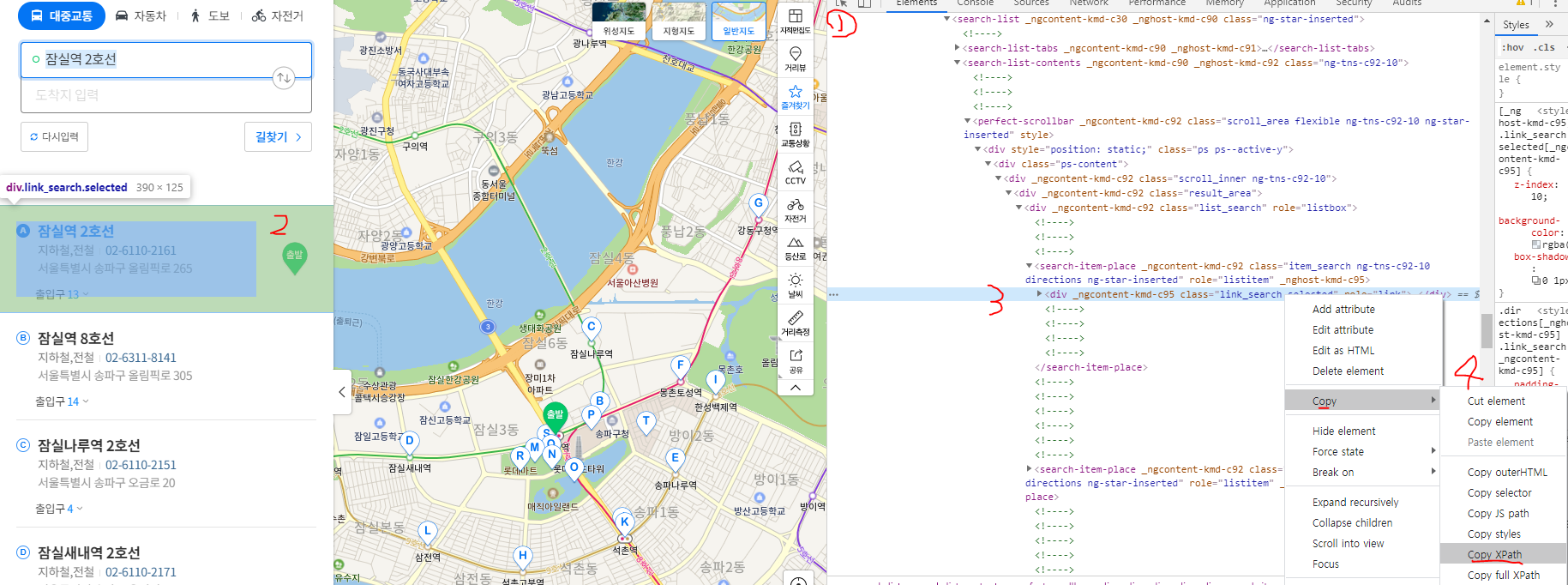
잠실역 2호선을 클릭해야 합니다. 만약 클릭을 안 하게되면 빈값이 들어가게 됩니다.
xpath의 값은 다음과 같습니다.
//*[@id="container"]/div[1]/shrinkable-layout/directions-layout/directions-result/directions-search-list/search-list/search-list-contents/perfect-scrollbar/div/div[1]/div/div/div/search-item-place/div
이제 잠실역 2호선, 신사역2호선을 입력 받았습니다. 받게 되면 이제 '길찾기'라는 버튼을 클릭해야 됩니다.
다음과 같습니다.
btn btn direction.active
하지만, 위의 있는 값을 소스코드에서 값을 넣을 때 띄어쓰기를 하면 안됩니다.
밑에 보시면 충분히 이해하실거라 믿습니다.

전체 소스코드를 보여드리겠습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('chromedriver')
driver.get('https://map.naver.com/v5/directions/-/-/-/?c=14139078.9231079,4509745.6215210,15,0,0,0,dh')
#네이버 길찾기 주소
driver.find_element_by_xpath('//*[@id="intro_popup_close"]/span').click()
delay = 3
driver.implicitly_wait(delay) # 3초 기달림
driver.find_element_by_id('directionStart').send_keys('잠실역')
driver.find_element_by_id("directionStart").send_keys(Keys.RETURN) # 엔터
driver.find_element_by_xpath('//*[@id="container"]/div[1]/shrinkable-layout/directions-layout/directions-result/directions-search-list/search-list/search-list-contents/perfect-scrollbar/div/div[1]/div/div/div/search-item-place/div').click()
driver.find_element_by_id('directionGoal').send_keys('신사역')
driver.find_element_by_id('directionGoal').send_keys(Keys.RETURN)
try :
#driver.find_element_by_xpath('//*[@id="container"]/div[1]/shrinkable-layout/directions-layout/directions-result/div/directions-search/div[2]/button[2]').click()
driver.find_element_by_class_name('btn.btn_direction.active').click()
except:
print('1')
만약 안 될 시에는 다음과 같은 소스코드로 해보시길 바랍니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('chromedriver')
driver.get('https://map.naver.com/v5/directions/-/-/-/?c=14139078.9231079,4509745.6215210,15,0,0,0,dh')
#네이버 길찾기 주소
driver.find_element_by_xpath('//*[@id="intro_popup_close"]/span').click()
delay = 3
driver.implicitly_wait(delay) # 3초 기달림
driver.find_element_by_id('directionStart').send_keys('잠실역')
driver.find_element_by_id("directionStart").send_keys(Keys.RETURN) # 엔터
try :
driver.find_element_by_xpath('//*[@id="container"]/div[1]/shrinkable-layout/directions-layout/directions-result/directions-search-list/search-list/search-list-contents/perfect-scrollbar/div/div[1]/div/div/div/search-item-place/div').click()
except :
driver.find_element_by_id('directionGoal').send_keys('신사역')
driver.find_element_by_id('directionGoal').send_keys(Keys.RETURN)
try :
driver.find_element_by_class_name('btn.btn_direction.active').click()
except:
print('1')
try 문과 except만 넣었습니다.
음, 뭐가 문제인지는 추후에 넣어보겠습니다. 댓글로 말씀해주시면 감사합니다.
결과는 다음과 같습니다.

이상 포스터를 마치겠습니다.
'파이썬' 카테고리의 다른 글
| 파이썬 & 데이터베이스 연동(TinyDB) - 2탄 (0) | 2020.04.22 |
|---|---|
| 파이썬 & 데이터베이스 연동(TinyDB) - 1탄 (0) | 2020.04.22 |
| 파이썬 크롤링 네이버 API 애플리케이션 등록하기 - 1 (0) | 2020.04.19 |
| 맥 파이썬 설치 및 2.7버전에서 3.x으로 변경하기 (2) | 2020.04.19 |
| 파이썬 pdf파일을 text, html로 바꾸는 법 (2) | 2020.04.10 |