이번 장에서는 뷰티풀솝의 중요한 부분을 설명드리겠습니다.
바로 소스코드를 보겠습니다. 여기서 중요한 것은 .find입니다.
import bs4
html_str = "<html><div>hello</div></html>"
bs_obj = bs4.BeautifulSoup(html_str, "html.parser")
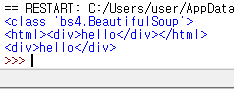
print(type(bs_obj)) #bs_obj 변수 타입 출력
print(bs_obj) #<html> <div> ~~ 이부분 출력
print(bs_obj.find("div")) # 여기서 .find는 찾는다라는 뜻으로 해석하시면 됩니다. 즉, div를 찾는다.
결과
다음 예시를 보겠습니다.
import bs4 html_str =
""" <html>
<body>
<ul> <li>hello</li>
<li>bye</li>
<li>welcome</li>
</ul>
</body
</html> """
bs_obj = bs4.BeautifulSoup(html_str ,"html.parser")
ul = bs_obj.find("ul") #ul를 찾습니다.
li = ul.find("li") print(li) # ul안에 li라는 것을 찾습니다.
#결과는 어떨까요? 분명 <li>hello</li>라는 것이 뜰겁니다.
#저기서 li라는 곳이 거슬리지 않나요? 지구에서 소멸하는 방법^^을 알려드리겠습니다.
# .text속성을 사용하면 됩니다.
print(li.text)
#findAll을 써보겠습니다. findAll은 모든 요소를 리스트[] 형태로 추출해주는 기능입니다.
li1 = ul.findAll("li")
print(li1[1]) # bye를 뽑기위한 인덱스 li1[0]은 뭐죠? <hello>입니다.
# 분명 위의 print는 <li> bye</li>라는 결과가 나올 것입니다. <li>라는 부분을 없앨려면 어떻게 해야되죠?
print(li[1].text)
결과

이런 식으로 결과가 뜨게 됩니다. 좀 지루하죠? 개념부터 차근차근이 하기에는 너무 많기 때문에 다음 절에는 점프해서 재밌는 것을 해보겠습니다. 하지만, beautifulsoup의 속성만 알아두면 좋을 것 같습니다.
- .find() 특정 한 곳을 찾는다.
- .text ex) print(li.text) html태그를 지워버린다. 위에 참조
- .findAll() 모든 요소를 리스트[] 형태로 추출해주는 기능
- 뷰티풀솝을 사용하려면 HTML지식이 있어야 일단 재미를 위해서 해봅시다.
'파이썬' 카테고리의 다른 글
| Python Selenium(셀레늄) 설치 및 사용법 (0) | 2020.03.26 |
|---|---|
| 크롤링 하기5 - 네이버에서 특정 글자 추출 및 네이버 파싱 (0) | 2020.03.25 |
| 크롤링 하기3 - 뷰티풀솝 사용 및 설치 (0) | 2020.03.22 |
| 크롤링 하기2- 네이버 크롤링하기 (0) | 2020.03.22 |
| 크롤러 만들기1 (파이썬 설치 하신 분들만) (0) | 2020.03.22 |

